
Abhay Mittal
Multimodal researcher at Meta. I work on generative models that try to unify vision, language, speech, and motion.
I'm a researcher at Meta working on multimodal generative models. My work centers on unifying vision, language, speech, and motion in a single model, modality alignment and catastrophic forgetting in multimodal training, and real-time, long-horizon generation - all aimed at making generative systems capable enough to act as embodied agents.
Before Meta, I worked at Amazon on multimodal models that generalize with limited supervision, image and video recognition, and visual reasoning. Previously, I did my M.S. in Computer Science at the University of Massachusetts, Amherst, advised by Prof. Subhransu Maji and Prof. Daniel Sheldon, where I built semantic segmentation models to measure historical bird migration from weather radar data. Earlier, I spent a brief stretch at Adobe and earned my B.Tech in Computer Engineering from Aligarh Muslim University, India.
Off the clock: slower books, a steady diet of papers on topics I'm curious about, and weekends in the Cascades.
Open to collaborations and advisory chats. If you're working on multimodal learning, embodied agents, or building something adjacent - drop a line. Always up for comparing notes.
Selected work
-
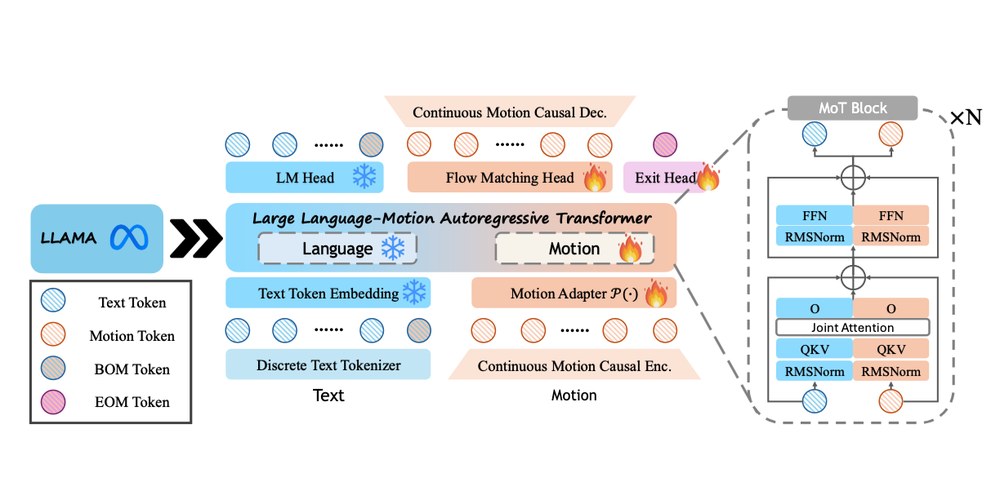
Extends pretrained LLMs to human motion generation and understanding while preserving native language performance; motion uses a continuous representation via a conditional flow-matching head, while text remains discretely tokenized.
-
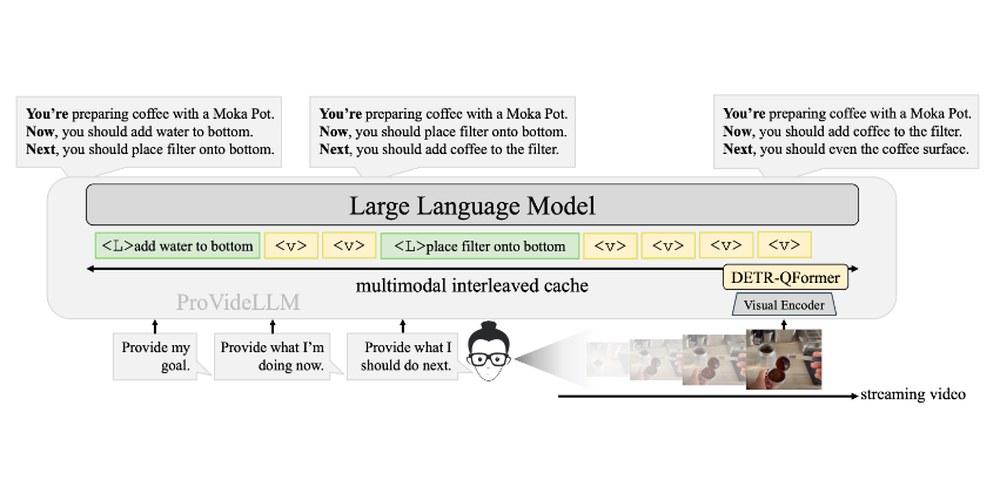
Memory-efficient Streaming VideoLLMs for Real-time Procedural Video Understanding
A multimodal cache for long streaming procedural videos - verbalized text holds long-term context, while a QFormer-based architecture preserves short-term visual detail.
-
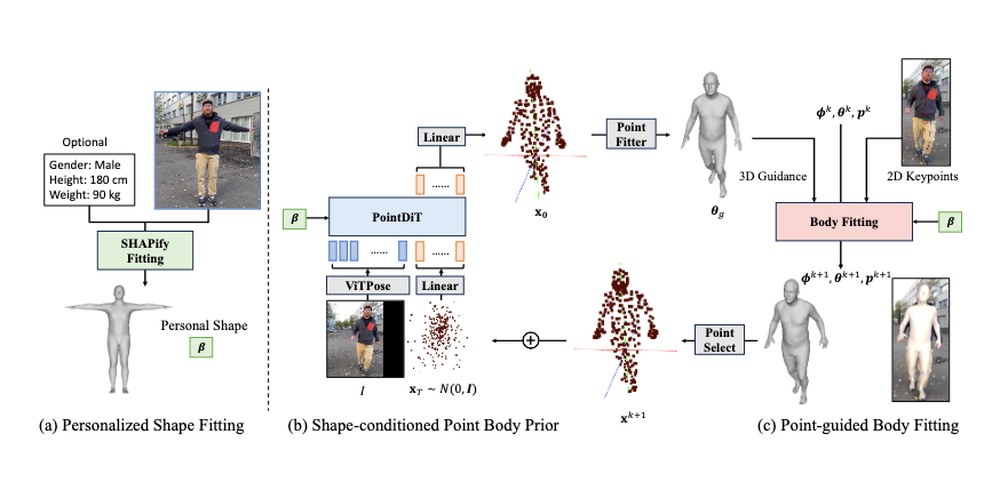
PHD: Personalized 3D Human Body Fitting with Point Diffusion
Extracts 3D human body poses from video via a shape-conditioned 3D point diffusion prior.
-
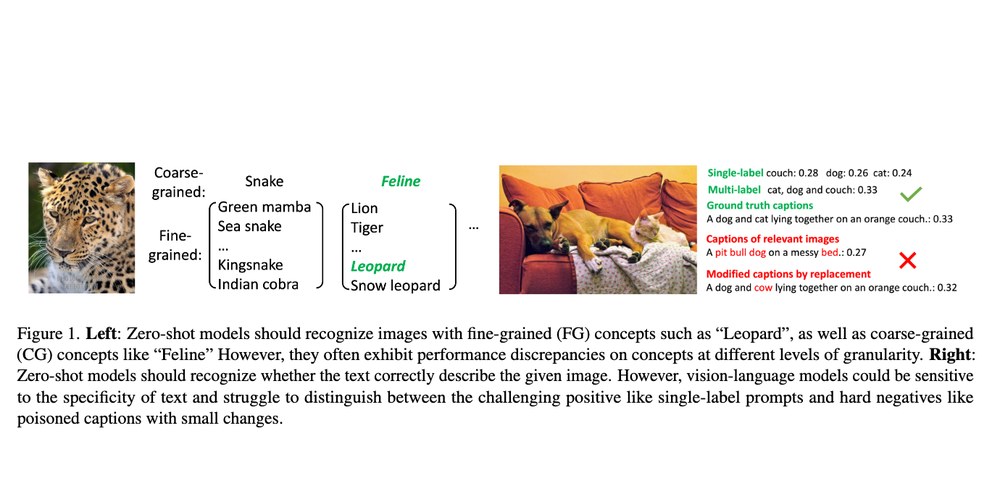
Studies how CLIP-style VLMs behave across semantic granularities and how reliably they distinguish subtly-incorrect textual descriptions.
-
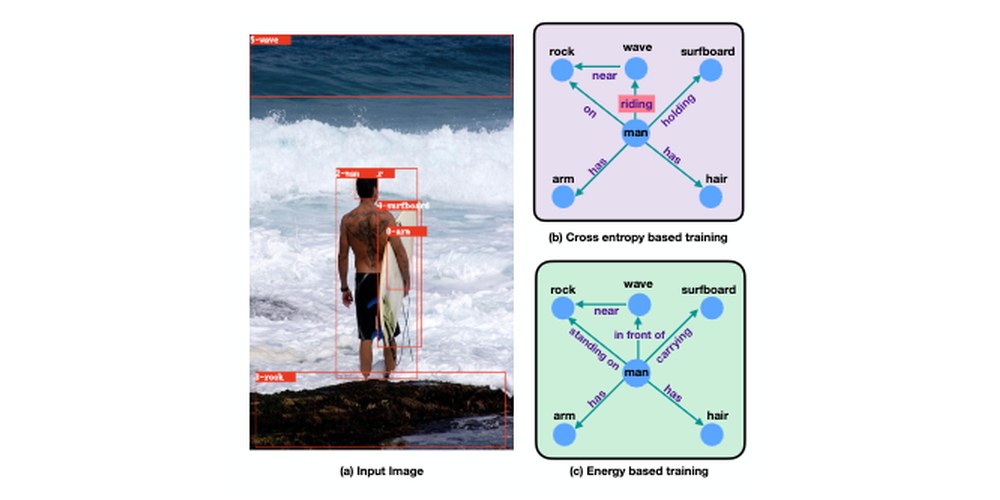
Energy-Based Learning for Scene Graph Generation
An energy-based learning framework that models global structural consistency in scene graph generation.